认识 PyTorch 1.12 之后的 nvFuser
NVFuser 技术
nvFuser 是一种深度学习编译器,可快速灵活的即时编译(JIT, Just-in-time) GPU 特定代码,以可靠地自动加速用户的网络,通过在运行时生成快速自定义“融合”内核,为在 Volta 和后来的 CUDA 加速器上运行的深度学习网络提供加速。nvFuser 专为满足 PyTorch 社区的独特需求而设计,它支持各种网络架构和程序,支持动态输入(不同shape, strides)。nvFuser 基于 Torchscript 对计算图进行优化和加速。我们一般是需要将PyTorch Eager模式的动态图模型转化为 Torchscript IR表示的计算图,然后再让nvFuser 在特定 GPU 设备上优化模型。 该技术从 PyTorch 1.12 全面引入。
算子融合是基本的优化策略
- 计算少, memory moving 是非常耗时的
- Fusion is primarly the optimization of keeping intermediate values in cache or registers
- Fusion is user defined operations -> efficient device specific code
nvFuser 当前支持什么?
- Backward pass
- bool, int32, int64, fp16, bfloat16, fp32, fp64
- pointwise ops, reductions, normalizations, view dynamic shape
- Coming soon: Channels last(performance), Complex, Transpose, Pooling Layers, Mattel
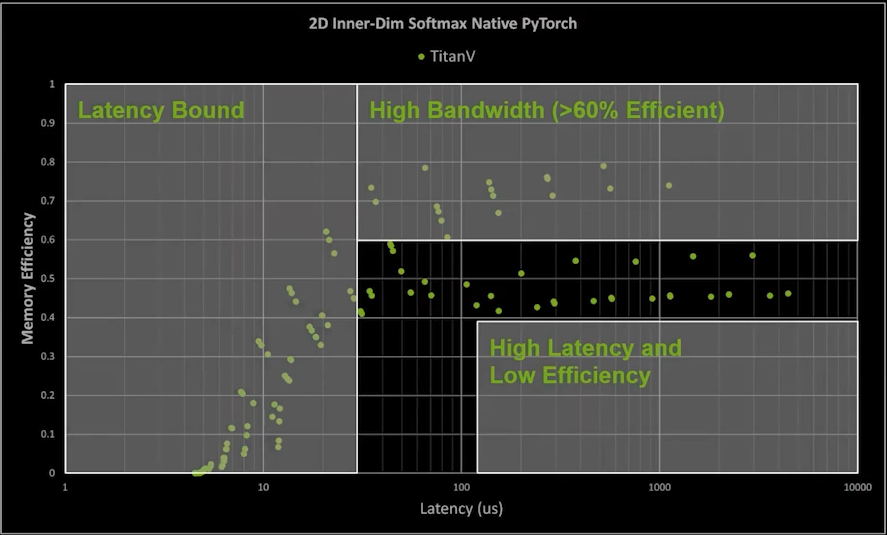
Memory Efficiency: Assumes an op can be done in a single function and fits into cache. This is not always possible.
nvFuser 提升推理过程Memory Efficiency, 大约提升10%+
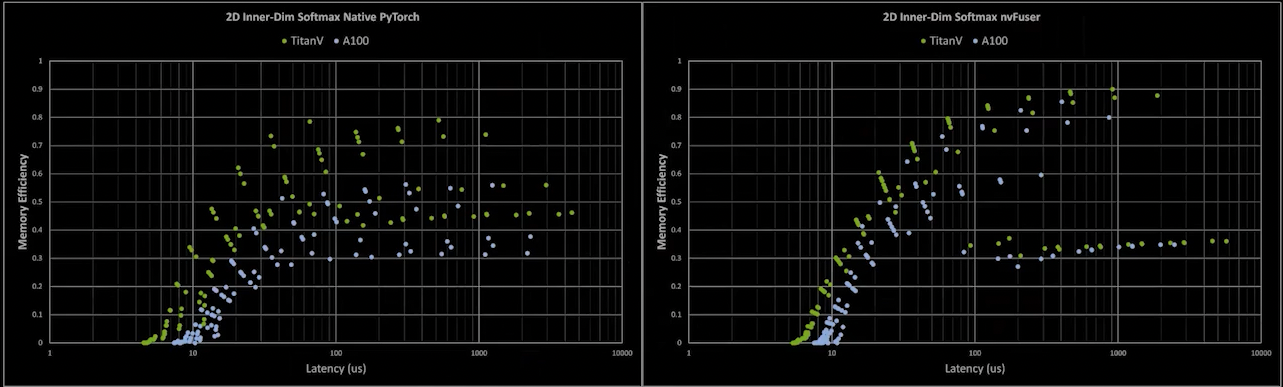
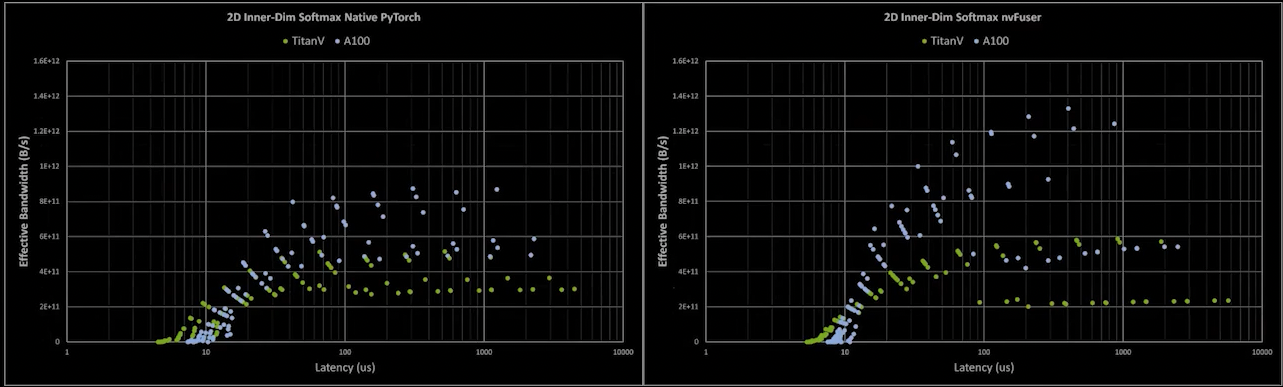
The Next Generation of GPU Performance in PyTorch with nvFuser
nvFuser in PyTorch
当前主要有三种机制可以将 PyTorch 模型进行 capture, translate and pass,来输出可以让nvFuser的程序:
Torchscript.jit.script
FuncTorch
该体系不直接查看用户 Python 脚本,而是在运行时通过插入对 PyTorch Op状态的capture机制。 我们将这种类型的捕获系统称为“跟踪程序获取 (trace program acquisition)”,因为我们正在跟踪已执行的操作。 FuncTorch 不执行自己的自动微分——它只是直接跟踪 PyTorch 的 autograd 以获得向后图。
TorchDynamo
TorchDynamo 是另一种建立在 FuncTorch 之上的程序获取机制。 TorchDynamo 解析从用户脚本生成的 Python 字节码,以便选择要使用 FuncTorch 跟踪的部分。 TorchDynamo 的好处是它能够将装饰器应用于用户的脚本,有效地隔离应该发送给 FuncTorch 的内容,使 FuncTorch 更容易成功地跟踪复杂的 Python 脚本。
上面这三类机制可供用户直接交互,而 nvFuser 会自动无缝地优化用户代码的性能关键区域。 这些系统自动将解析后的用户程序发送到 nvFuser,以便 nvFuser 可以:
分析在 GPU 上运行的操作
为这些操作规划并行化和优化策略
在生成的 GPU 代码中应用这些策略
Runtime-编译生成的优化 GPU 函数
在后续迭代中执行那些 CUDA 内核
重要的是要注意 nvFuser 尚不支持所有 PyTorch Op,并且在此处讨论的 nvFuser 中仍有一些正在积极改进的场景。 然而,nvFuser 今天确实支持许多 DL 性能关键 Op,并且支持的 Op 数量将在后续的 PyTorch 版本中增加。 nvFuser 能够为其支持的操作生成高度专业化和优化的 GPU 函数。 这意味着 nvFuser 能够为 TorchDynamo 和 FuncTorch 等新的 PyTorch 体系提供动力,以将 PyTorch 灵活性与无与伦比的性能相结合。
NVFuser 的应用
控制nvFuser 开关
- Allow single node fusion
torch._C._jit_set_nvfuser_single_node_mode(True)Fusion group is only created when two or more compatible ops are grouped together. Turn on single node fusion would allow fusion pass to create fusion group with a single node, this is very handy for testing and could be useful when single node generated kernel out-performs native cuda kernels in framework. - Allow horizontal fusion
torch._C._jit_set_nvfuser_horizontal_mode(True)Fusion pass fuses producer to consumer, horizontal mode allows sibling nodes that shared tensor input to be fused together. This could save input memory bandwidth. - Turn off guard for fusion
torch._C._jit_set_nvfuser_guard_mode(False)This disables the runtime check on fusion group pre-assumptions (tensor meta information / constant inputs / profiled constants), this really is only used for testing as we want to ensure generated kernels are indeed tested and you should avoid using this in training scripts. - Turn off fusion for certain node kinds
torch._C._jit_set_nvfuser_skip_node_kind("aten::add", True)This disables fusion for certain nodes, but allows other nodes to continue being fused. The first parameter is the node kind, and the second parameter is whether to toggle the node on or off in fusion.
1 | import torch |
PYTORCH_JIT_LOG_LEVEL="profiling_graph_executor_impl" python <your pytorch script>
打印出的计算图很简单,您应该寻找 prim::CudaFusionGroup_X
以获取融合内核。 虽然分析执行器会转储很多东西,但最重要的部分是优化图。
在这个例子中,它显示了一个融合组,这表明融合正在发生,你应该期待融合内核!
请注意,在进行训练时,autodiff 可能会阻止 Op 融合 。 Fusion pass 仅在 prim::DifferentiableGraph 中运行,因此你应该首先检查目标操作是否在可微分图子图中。 计算图 Dump 后看起来非常混乱,因为它直接 dump 所有由分析执行器执行的计算图,而可微分计算图是通过嵌套计算图执行器执行的。 因此,对于每个模型,你可能会看到一些分段优化的子图,其中每个子图都对应于原始图中的一个可微分节点。
1 | Before Fusion: |
Cuda fusion dump 将输入和输出图提供给 fusion pass。 这种方式可以用来检查融合传递逻辑。
PYTORCH_JIT_LOG_LEVEL="graph_fuser" python <script_name>
我们从结果中可以看到有两个计算图:
- Fusion pass 执行之前对应的计算图
- Fusion pass之后的计算图,其中包括两个 CudaFusionGroup,每个 CudaFusionGroup 将触发代码生成系统去生成 Kernel 来执行子图。
1 | [DUMP graph_fuser.cpp:2352] Before Fusion: |
NVFusion 的性能评估
TIMM 模型
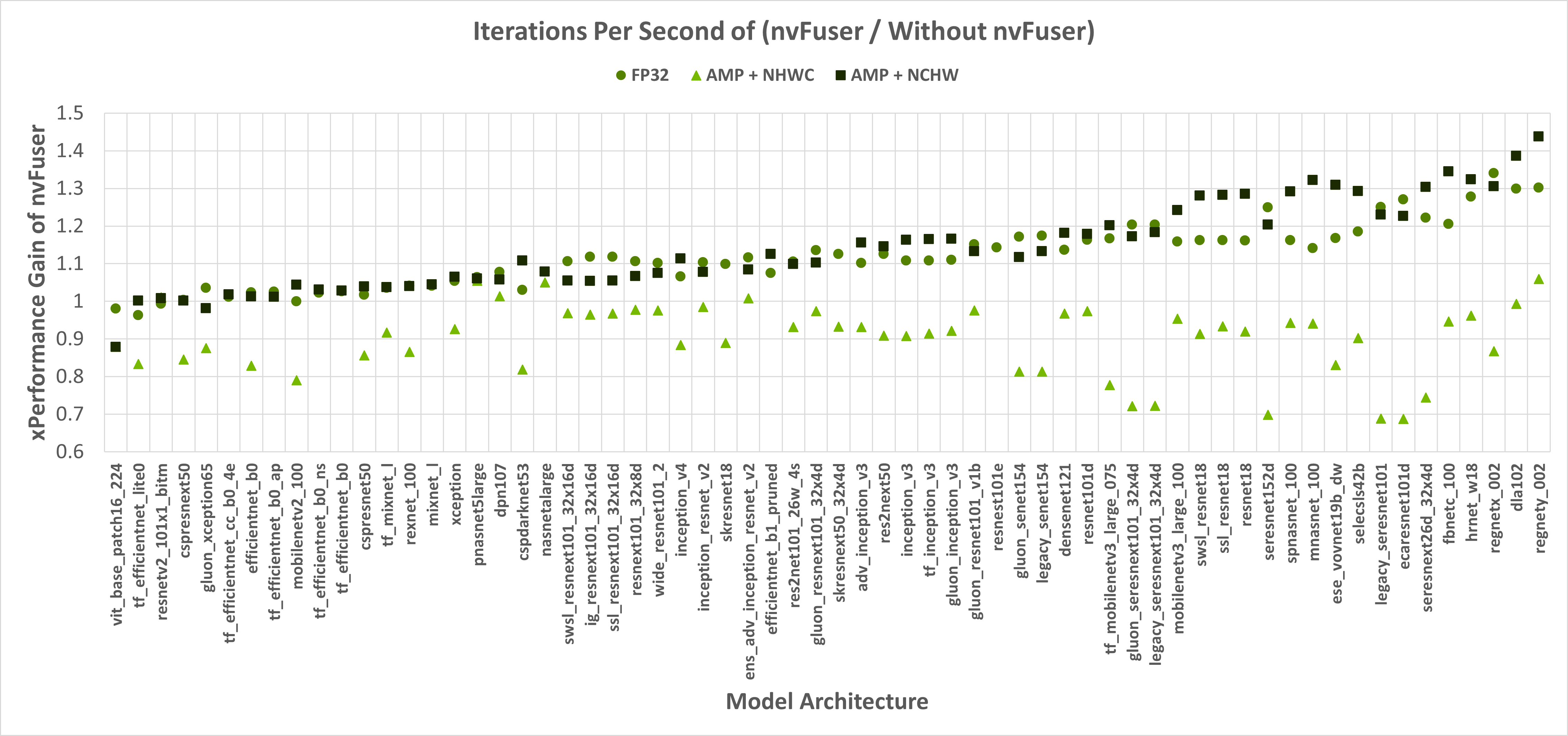
nvFuser, can also significantly reduce the training time of TIMM networks, up to over 1.3x vs. eager PyTorch, and up to 1.44x vs. eager PyTorch when combined with the torch.amp module. Figure 1 shows nvFuser’s speedup without torch.amp, and when torch.amp is used with the NHWC (“channels last”) and NCHW (“channels first”) formats. nvFuser is integrated in TIMM through FuncTorch tracing directly (without TorchDynamo) and can be used by adding the –aot-autograd command line argument when running the TIMM benchmark or training script.
FuncTorch: memory_efficient_fusion
- Eager Mode - Primitive Definition: Average iterations per second: 591.93
- TorchScript - Primitive definition: Average iterations per second: 1657.58
- FuncTorch - Primitive definition: Average iterations per second: 2918.51
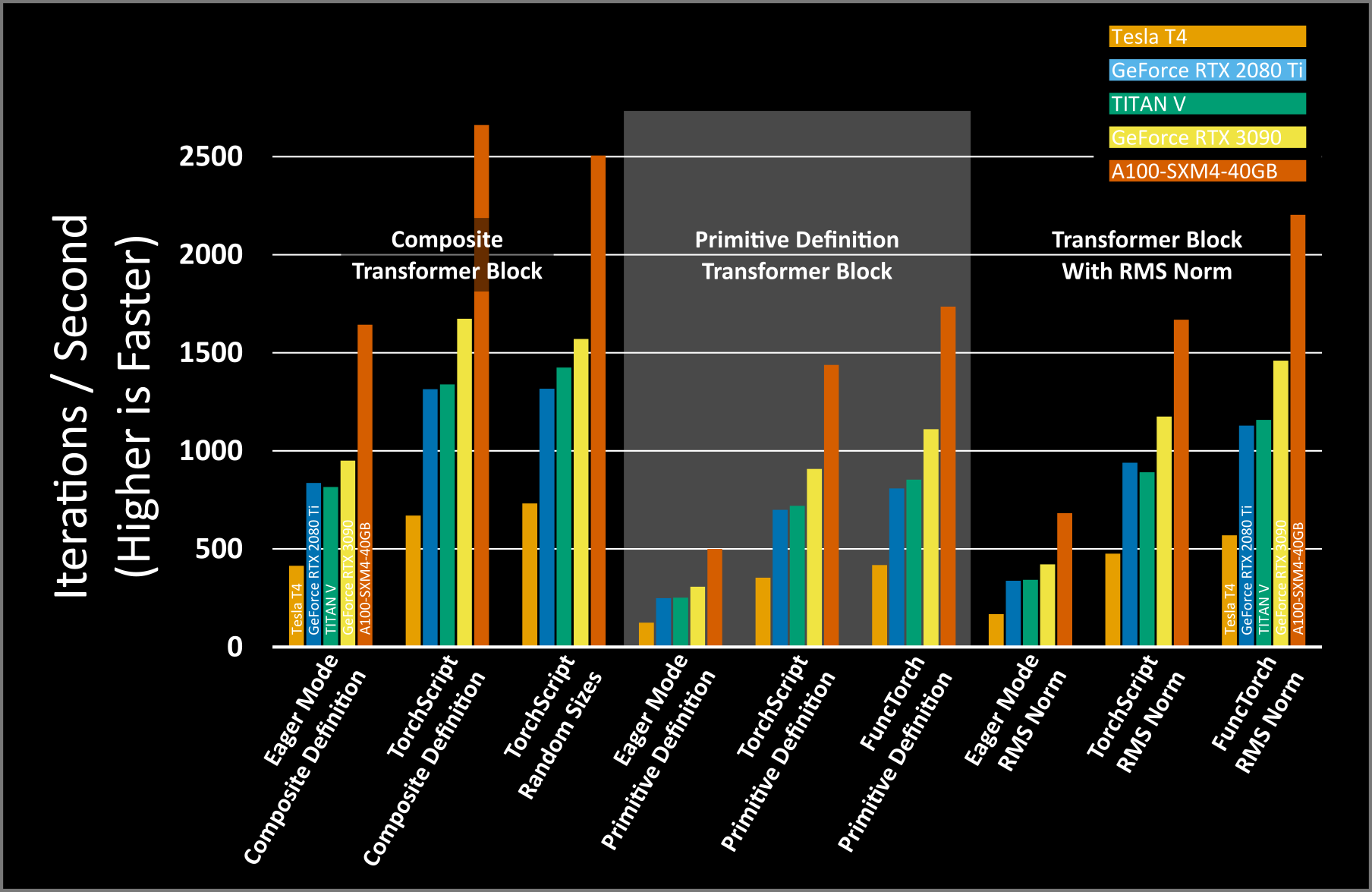
从结果中来看,新版本中的nvFuser 方法比原来的 Torchscript方式性能进一步提升。
fuser上下文
一行代码,在 efficient net-b3 中的性能提升情况。
1 | import torch |
| Model | Engine | Batch_size | time(ms)/per image | |
|---|---|---|---|---|
| EfficientNet-b3_224 | PyTorch-1.11 | 1 | 14.780 | |
| PyTorch-1.11 | 4 | 4.2275 | ||
| PyTorch-1.11 | 8 | 2.0720 | ||
| PyTorch-1.11 | 16 | 1.0915 | ||
| EfficientNet-b3_224 | PyTorch-1.12 | 1 | 14.7769 | PyTorch版本不同 |
| PyTorch-1.12 | 4 | 4.1610 | ||
| PyTorch-1.12 | 8 | 2.0671 | ||
| PyTorch-1.12 | 16 | 1.0677 | ||
| EfficientNet-b3_224 | Torchscript-1.11 | 1 | 10.7 | |
| Torchscript-1.11 | 4 | 3.8995 | ||
| Torchscript-1.11 | 8 | 2.3749 | ||
| Torchscript-1.11 | 16 | 1.6607 | ||
| EfficientNet-b3_224 | Torchscript-1.12 | 1 | 9.7512 | |
| Torchscript-1.12 | 4 | 2.9710 | ||
| Torchscript-1.12 | 8 | 1.4233 | ||
| Torchscript-1.12 | 16 | 0.7389 | trochscript1.12性能提升30% | |
| EfficientNet-b3_224 | Torchscript-1.12-fuser0 | 1 | 7.8338 | legacy fuser |
| Torchscript-1.12-fuser0 | 4 | 2.1315 | legacy fuser | |
| Torchscript-1.12-fuser0 | 8 | 1.1117 | legacy fuser | |
| Torchscript-1.12-fuser0 | 16 | 0.5922 | legacy fuser | |
| EfficientNet-b3_224 | Torchscript-1.12-fuser1 | 1 | 6.7735 | NNC |
| Torchscript-1.12-fuser1 | 4 | 1.8711 | NNC | |
| Torchscript-1.12-fuser1 | 8 | 0.9110 | NNC | |
| Torchscript-1.12-fuser1 | 16 | 0.5894 | NNC | |
| EfficientNet-b3_224 | Torchscript-1.12-fuser2 | 1 | 7.9868 | NVFuser |
| Torchscript-1.12-fuser2 | 4 | 2.2119 | NVFuser | |
| Torchscript-1.12-fuser2 | 8 | 1.0809 | NVFuser | |
| Torchscript-1.12-fuser2 | 16 | 0.5914 | NVFuser |
参考链接
- https://pytorch.org/blog/pytorch-1.12-released/
- https://github.com/pytorch/pytorch/tree/release/1.12/torch/csrc/jit/codegen/cuda
- https://pytorch.org/blog/introducing-nvfuser-a-deep-learning-compiler-for-pytorch/
- https://pytorch.org/tutorials/intermediate/nvfuser_intro_tutorial.html
- https://www.nvidia.com/en-us/on-demand/session/gtcspring21-s31952/